





1. Qu'est-ce que le deep learning ?▲
Ce document a pour seule ambition de vous faire comprendre simplement ce qu'est le deep learning (ou apprentissage profond) à travers des exemples simples tels que le jeu de tic-tac-toe, Alpha Go, la reconnaissance d'images, etc. Nous verrons des exemples d'applications et jetterons un œil sur les perspectives pour l'avenir.
L'apprentissage profond est un ensemble de méthodes d'apprentissage automatique utilisables pour modéliser à un haut niveau d'abstraction des données et avec lesquelles la machine apprend par elle-même à réaliser une tâche donnée. Par exemple, lorsque l'on parle de reconnaissance d'images, le système apprend automatiquement à classifier les images en différentes catégories selon le jeu de données qui lui est fourni pour reconnaître, par exemple, une automobile ou une motocyclette sur une image. Cela peut sembler confus, mais nous allons voir au fil de ce document que le fonctionnement sous-jacent n'est pas si compliqué qu'il n'y paraît.
Pour résumer l'apprentissage profond, nous allons nous appuyer sur une citation extraite du livre Deep Learning de Yann Goodfellow qui nous dit : « Solving the tasks that are easy for people to perform but hard for people to describe formally », ce que l'on peut traduire ainsi : « Résoudre des tâches faciles à accomplir, mais difficiles à décrire formellement. » Par exemple, il est facile pour quiconque de reconnaître un chat sur une image. En revanche, décrire pourquoi ce que l'on voit est un chat ne peut pas être décrit simplement à l'aide d'un système de règles. C'est là que l'apprentissage automatique intervient.
Prenons le cas d'un système de traduction automatique de texte. Si on lui donne une phrase, le système va automatiquement la traduire, car il l'aura appris « tout seul ». Il y a lieu de se demander comment ça peut fonctionner, comment un système peut apprendre tout seul. C'est ce que nous allons découvrir ensemble.
2. Exemple d'un jeu de tic-tac-toe▲
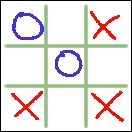
Pour commencer à comprendre un peu mieux ce qu'est un apprentissage, nous allons prendre l'exemple du tic-tac-toe (ou jeu de morpion). Tout le monde connaît plus ou moins bien ce jeu : on dispose d'un quadrillage 3 x 3 de neuf cases, chaque joueur joue à tour de rôle en marquant une case avec un cercle ou une croix, celui qui réussit le premier à aligner trois signes a gagné.
Ce jeu accepte 765 combinaisons différentes, et il y a 26 830 parties possibles (aux rotations ou symétries près). Le système de règles décrivant une stratégie gagnante est simple et très facile à modéliser. On peut très facilement dire : dans cette configuration-là, je vais jouer ici ou là, parce que j'aurai plus de chance de faire une ligne, alors que si je joue à tel autre endroit, je ne pourrai pas faire de ligne. Dans l'illustration ci-dessus, on remarque très facilement que la position est gagnante au prochain coup pour le joueur aux croix rouges, quel que soit le coup du joueur aux ronds bleus.
3. Le jeu de go▲
Le nombre de possibilités de jeux sur la grille 3 x 3 du tic-tac-toe est très limité et donc très simple à modéliser avec un système de règles, avec des conditions : si cette case est remplie avec une croix, alors je fais ceci, et ainsi de suite.

Mais quand on s'attaque à des jeux nettement plus complexes, comme le jeu de go, tout devient beaucoup plus compliqué. Le jeu est constitué d'une grille (le goban) de 19 lignes horizontales et de 19 lignes verticales, dont les intersections matérialisent 361 emplacements sur lesquels les joueurs posent des « pierres » (généralement des jetons blancs ou noirs). Le jeu est bien plus tactique et stratégique. Il ne s'agit plus d'aligner trois pions, mais de constituer des territoires et emprisonner des pierres adverses ; vous allez jouer avec des perspectives beaucoup plus profondes. Mon adversaire a joué là, donc, peut-être que, dans deux coups, il a l'intention de me faire ce coup inattendu.
Il y a environ 10170 positions possibles au jeu de go et l'arbre des possibilités de jeu est de l'ordre de 10600. De tels chiffres rendent évidemment toute recherche exhaustive impossible. Il n'est pas envisageable de modéliser un jeu de ce genre avec un système de règles pré-écrites par des êtres humains. Il reste possible de modéliser le jeu, mais avec une approche et un niveau d'intelligence artificielle très différents.
Quand la machine a réussi à battre des humains au jeu de go
En mai 1997, quand le superordinateur DeepBlue d'IBM a battu le champion du monde d'échecs Garry Kasparov, les ordinateurs étaient encore bien incapables de battre un joueur de go, même relativement moyen. Ainsi, la même année, en 1997, Janice Kim, joueuse de go professionnelle, battait le programme HandTalk malgré un handicap de 25 pierres en faveur de la machine. En 1998, Martin Müller, sixième dan amateur, battait Many Faces of Go malgré un handicap (énorme) de 29 pierres.
Depuis, les progrès de la machine ont été spectaculaires. En octobre 2015, le programme AlphaGo de la société Google DeepMind a réussi à battre pour la première fois un joueur humain professionnel (le Franco-Chinois Fan Hui, actuellement meilleur joueur d'Europe). En mars 2016, lors d'un match très médiatisé à Séoul, ce programme a réussi à battre 4-1 le Sud-Coréen Lee Sedol (neuvième dan professionnel), l'un des meilleurs joueurs mondiaux. En mai 2017, juste vingt ans après la défaite historique de Kasparov aux échecs, AlphaGo battit le numéro 1 mondial du jeu de go, le Chinois Ke Jie (voir par exemple cette actualité).
C'est ce que le programme AlphaGo a réussi à résoudre, et il a réussi à battre les meilleurs joueurs du monde tout simplement parce que le système n'était pas basé sur des règles pré-écrites par un humain. Ce sont des règles très difficiles à modéliser - on parle ici non pas des règles du jeu, mais de la façon de jouer qui permet de gagner.
Le système apprenant a réussi à « comprendre » comment un être humain jouait et donc comment il pouvait jouer pour battre un humain. Un système apprenant a beaucoup plus de capacités, puisqu'il apprend par lui-même ; il n'est pas limité aux simples règles qu'on lui dicte. Il va avoir les règles qu'on lui donne, mais, dans ce champ des possibles, il va pouvoir trouver de lui-même de nouvelles solutions à explorer, et c'est cela qui est vraiment intéressant.
Il est bon de revenir ici à la citation d'Ian Goodfellow sur l'apprentissage profond : « Résoudre des tâches qui sont faciles à accomplir, mais difficiles à décrire formellement ».
Prenons l'exemple d'une partie d'échecs. Si je vous demande d'expliquer pourquoi vous avez joué un certain coup, beaucoup de paramètres vont entrer en ligne de compte. Il n'y a en général pas de règle disant que, dans telle position, vous devez jouer tel ou tel coup. Le jeu est régi par énormément de règles, et, bien souvent, vous ne pouvez pas décrire simplement le pourquoi. Dans une telle situation, il devient compliqué de modéliser le jeu par un système de règles. Il est relativement facile de jouer aux échecs ou aux dames, mais c'est très difficile à décrire.
4. La reconnaissance d'image▲
Prenons un autre exemple. Considérons l'image ci-dessous.

Que représente cette image ? C'est un chat. Il est très facile pour un être humain de reconnaître que c'est un chat. En revanche, si je vous demande pourquoi c'est un chat, vous aurez sans doute de grandes difficultés à justifier cette affirmation, du moins au-delà de : « ça se voit ». Ou alors, vous pourriez dire : « Eh bien, il a des yeux, des oreilles, il a des poils, un pelage un peu rayé, des moustaches, etc. » Mais cela ne suffit pas vraiment à identifier un chat. Comment peut-on faire entrer une définition de chat dans un système de règles ?
On peut imaginer plusieurs méthodes, par exemple avoir un détecteur d'yeux, un détecteur d'oreilles, un détecteur de pattes, et ainsi de suite. Ça devient compliqué parce que, selon les images, le contraste autour des yeux est différent, la couleur des yeux est différente, l'angle de la tête est différent et ainsi de suite. On ne pourrait pas en fait reconnaître à coup sûr que c'est un chat simplement à l'aide d'un système de règles ou une formule mathématique toute bête qui nous dirait que, ça, c'est une forme de chat. Ce n'est pas possible.
On va donc devoir apprendre au système que c'est un chat ; ou, plutôt, c'est le système qui va devoir comprendre et apprendre par lui-même que c'est un chat.
C'est comme cela que fonctionne un être humain et c'est ce que nous avons appris à faire depuis que nous sommes tout petits. Si je vous montre ces deux signes :

et que je leur donne un nom arbitraire ; par exemple j'appelle « B » le signe de gauche et « A » celui de droite. Donc, je vous dis : à gauche c'est le signe « B » et à droite le signe « A », et vous mémorisez cette information. Maintenant, si je vous montre ceci :

Vous allez reconnaître que c'est le signe « B ». Vous avez mémorisé l'image et, si je vous la remontre, vous êtes capables de dire ce que c'est.
Mieux encore, si je vous montre un animal que vous n'avez jamais vu et vous dis ce que c'est, alors, si vous voyez cet animal dans un autre contexte, dans un environnement différent, vous allez tout de même être généralement capable de me dire que c'est le même animal. C'est la capacité de déduction d'un être humain.
Pour l'apprentissage automatique, il faudra procéder un peu différemment. On ne va pas pouvoir montrer au système une seule fois une image de chat et espérer qu'il soit capable de reconnaître d'autres chats. Il va falloir lui montrer, par exemple, un très grand nombre d'images de chats.

Ici, sur l'illustration, il y a seulement trois chats, mais, en réalité, on lui montre des milliers et des milliers d'images de chats, et on lui montre aussi un très grand nombre d'images de chiens :

On lui dit, toutes ces images, ce sont des chiens ; et toutes ces autres images, ce sont des chats.
Le système va devoir analyser les images et, ensuite, il va réussir à extraire dans les images ce qui fait que toutes celles-ci sont des chiens et toutes celles-là des chats. À la fin, le système ne verra plus l'arrière-plan, ou du moins l'arrière-plan n'aura plus d'importance pour lui : il aura compris que ce qui importe dans l'image, c'est la partie du chat qui permet de dire que c'est un chat, et celle d'un chien qui permet de dire que c'est un chien.
5. Applications de l'apprentissage profond▲
Les domaines d'application sont très vastes. Ce peut être la reconnaissance d'image, dont on vient de voir un exemple, mais aussi la détection d'objets, la reconnaissance vocale, la traduction automatique de texte, la compréhension du langage écrit ou parlé, la génération automatique d'images, et ainsi de suite. Il y a des applications médicales, par exemple pour l'établissement d'un diagnostic à partir d'une radiographie ou d'une autre forme d'image médicale, et il y a des applications dans la sécurité (analyse d'images de vidéosurveillance, reconnaissance faciale, etc.). La palette de sujets est pratiquement illimitée. L'un des thèmes les plus discutés au salon Mobile World Congress de Barcelone fin février et début mars 2018 était l'intégration des applications d'intelligence artificielle (reconnaissance vocale, traduction automatique, etc.) dans les téléphones mobiles (par opposition à l'appel à des services en ligne du même type actuellement offerts par Google ou d'autres opérateurs). C'est vraiment un thème à la mode.
Des recherches ont lieu dans toutes sortes de domaines. On en est à un stade où l'on a les méthodes, mais, parfois, pas encore l'application. On commence à en voir de très belles, comme les voitures autonomes ou dans le domaine médical, mais on est loin d'avoir exploré tous les sujets. L'émergence de l'apprentissage profond dans la vraie vie est un sujet très actuel. Certaines choses auxquelles on n'aurait même pas pensé il y a un an ou deux voient le jour, et d'autres dont on n'a pas idée aujourd'hui verront prochainement le jour.
La grande question concerne la façon dont on va intégrer tout cela pour que ce soit fonctionnel, utilisable par tout le monde et surtout fiable. Comme ce sont des systèmes apprenants, parfois on ne sait pas comment ils vont réagir. Le système peut faire des erreurs, il peut souvent faire aussi bien qu'un être humain, voire parfois mieux, mais peut-être aussi pas toujours aussi bien. La question actuelle est donc : comment gère-t-on cela dans la vraie vie pour déployer un système d'apprentissage profond qui soit fiable ?
6. Note de la rédaction de Developpez.com ▲
Ce texte a été rédigé par Laurent Rosenfeld à partir d'une vidéo de Thibault Neveu (C'est quoi le Deep learning ?)
Nous tenons à remercier Laurent Ott, dourouc05 et LittleWhite pour les judicieuses suggestions et jlliagre pour la relecture orthographique de ce tutoriel.
